Tutkimusaineistosta
Suomen yleiskielen äänteistössä on kahdeksantoista konsonanttia (d, h, j, k, l, ra, n, ŋ, p, r, s, t, v) ja kahdeksan vokaalia (a, e, i, o, u, y, ä, ö). Näistä vain ŋ:llä ei ole omaa kirjainmerkkiä eli grafeemia; se merkitään k:n edessä grafeemilla n ja sen geminaatta eli kaksoiskonsonantti grafeemiparilla ng. Yleiskielemme oikeinkirjoitus on siis poikkeuksellisen äänteenmukainen vaikkapa ruotsin tai englannin kieleen verrattuna; suomessa puheen foneemit ja kirjoituksen grafeemit vastaavat lähes ihanteellisella tavalla toisiaan.
Olen tutkinut suomen yleiskielen kirjainmerkkien esiintymistaajuksia ja niiden vaihteluita erilaisissa teksteissä sekä yrittänyt selvittää näiden taajuusvaihteluiden syitä. Materiaalinani on kaksi melko suurta tietokonepohjaista otosta. Pääkorpuksena, kielen-aineskokoelmana, on Oulun yliopiston suomen ja saamen kielen laitokseen vuosina 1968–1970 kerätty otos nykysuomen yleiskielestä. Aineiston perusjoukkona ovat 1) vuonna 1967 ilmestyneet suomenkieliset sanoma- ja aikakauslehdet, 2) vuosina 1961–1967 ilmestynyt alkuperäinen suomenkielinen tieto- ja kaunokirjallisuus, 3) Yleisradion radio-ohjelmat 29.9.1968–26.5.1969 sekä 4) 15 tuntia vuonna 1968 nauhoitettua ja kirjainnettua vapaata yleispuhekieltä. Käännöskieltä ei perusjoukossa ole. Tämä alkuteksti on luokiteltu 58 hypoteettiseksi alaluokaksi, joista kustakin on umpimähkäisotannalla valittu sata 5 virkkeen ja vähintään 60 saneen katkelmaa; jokaista alaluokkaa edustaa materiaalissa siis 500 virkettä ja vähintään 6 000 sanetta. Teksteistä on poistettu erikoismerkit ja -merkkiryhmät (esim. matemaattiset lausekkeet tms.), minkä jälkeen laskuihin on jäänyt 421 794 sanetta. Niiden keskipituus on 7,42 kirjainmerkkiä. Laskettavaksi koostuu tästä joukosta 3 130 382 grafeemia.
Toisena korpuksena tutkimuksissani on Esko Vierikon vuosina 1968–1969 koostama otos suomenkielisten kansanedustajien haastatteluista ja heidän eduskunnassa pitämistään virallisista puheista. Näistä muodostuu kaksi viimeistä alaluokkaa, joissa on yhteensä 112 606 sanetta (keskipituus 7,15 grafeemia) ja 804 771 kirjainmerkkiä.
Ynnättynä näistä kahdesta joukosta koostuu 534 400 sanetta eli tekstisanaa, joissa on 3 935 153 grafeemia; saneiden keskipituus on 7,36 grafeemia. Kirjakieltä on tästä määrästä vajaat kaksi kolmannesta (61,90 % saneista, 63,31 % grafeemeista): 330 799 sanetta, joissa on 2 491 208 grafeemia. Litteroitua yleispuhekieltä on siten kokonaismäärästä runsas kolmannes (38,10% saneista, 36,69 % grafeemeista): 203 601 sanetta, joissa on 1 443 945 grafeemia; puhekielen saneiden keskipituus on vain 7,09 grafeemia. – Grafeemit x ja z olen joutunut jättämään laskujeni ulkopuolelle, koska niitä on käytetty ainesta kerättäessä matemaattisten lausekkeiden, numerosarjojen, kemian kaavojen tms. sekä vielä puhekielen tunnistamattomien sanojen paikalla. Koska kirjaimistossamme ei ole merkkiä ŋ:lle, sisältää g-grafeemin frekvenssi sekä g:n että ŋ::n. Oletettavasti g on useimmiten ŋ:n merkkinä. Samoin grafeemi n on ŋ:n merkkinä, esimerkiksi (lanka :) langan -tapauksessa. Puhekielen kirjainnokset ovat enimmältään kirjakielen oikeinkirjoitusjärjestelmän mukaisia.
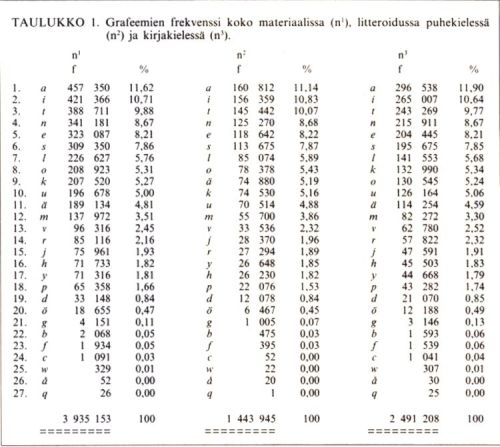
Taulukko 1 (pdf)
Kirjainmerkkien esiintymistaajuudet
Edellisen sivun taulukossa ovat aineistoni grafeemit esiintymistaajuutensa mukaisesti alenevassa järjestyksessä.
Kuten taulukosta näkyy, kirjakielen ja puhekielen kirjainnosten sekä koko materiaalin grafeemien esiintymisprosenteissa on melko suuriakin eroja. Kirjakielessä on esimerkiksi a:ta, u:ta ja ö:tä erittäin merkitsevästi enemmän kuin puhekielessä. Kaikkiaan näissä suurissa ryhmissä on peräti 20 grafeemin esiintymistaajuuksissa erittäin merkitseviä eroja (0,1 %:n riskillä).
Vokaalien merkkejä on koko aineistossani (n1) 1 886 561 (47,94 %), konsonanttien taas 2 048 592 (52,06 %). Vokaalien suhde konsonantteihin on 100 : 108,59. Joissakin vanhemmissa tilastoissa esitetyt luvut, joiden mukaan suomen kielessä olisi vokaaleja enemmän kuin konsonantteja, eivät tämän tilaston mukaan siis pidä paikkaansa. Mainittakoon, että Vilho Setälä päätyy Uuden testamentin kieleen perustuvissa laskelmissaan vastaaviin suhdelukuihin 100 : 109,49. – Aineistoni vokaalien keskinäinen yleisyysjärjestys on seuraava.
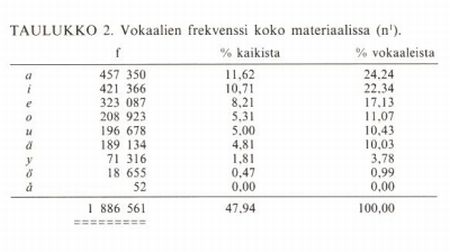
Taulukko 2(avautuu uuteen ikkunaan) (pdf)
Viiden etuvokaalin (i, e, ä, y, ö) esiintymien summa 1 023 558 on vähän yli puolet (54,26 %) kaikkien vokaalien summasta. Takavokaaleja (a, o, å, u) on 863 003 (45,74 % vokaaleista). 100:aa takavokaalia kohti on siten juoksevassa tekstissä 118,60 etuvokaalia. Suomen kielessä sekä etu- että takavokaalisissa sanoissa esiintyvät e ja i ovat varsin suurtaajuisia: niitä on yhteensä 744 453 eli 39,46 % vokaaleista (18,92 % kaikista grafeemeista).
Konsonanttigrafeemeja on aineistossani 2 048 592 (52,06 %). Ne on taulukoitu seuraavassa alenevaan yleisyysjärjestykseen.
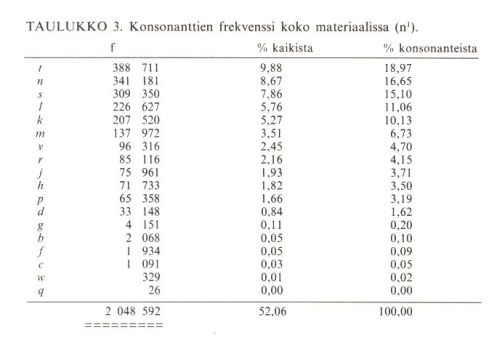
Taulukko 3 (pdf)
Konsonanttigrafeemeista muodostavat ylivoimaisesti suurimman ryhmän dentaalit (t, d, s, r, l, n): niiden esiintymiä on yhteensä 1 384 133, peräti 67,57 % kaikista konsonanteista. Labiaaleja (p, b, m, f, v) on 303 648 (14,82 %) ja palatovelaareja (k, g, j) lähes saman verran (287 632 eli 14,04 % kaikista konsonanteista). Soinnittomia klusiileja (k, t, p) on yhteensä lähes kolmannes kaikista konsonanteista (661 589 eli 32,29 %); niiden keskinäisissä yleisyyssuhteissa on huomattavan suuret erot.
Oletuksia erojen aiheuttajista
Tutkimani suuren aineiston ja esimerkiksi Vilho Setälän tutkiman Uuden testamentin suomennoksen grafeemien esiintymistaajuuksissa on varsin huomattavia eroja. Samoin on tilastollisesti erittäin merkitseviä eroja omassa materiaalissani vaikkapa kirjakielen ja puhekielen sekä lehtikielen, kaunokirjallisuuden kielen ja tietokirjallisuuden kielen grafeemistoissa.
On arveltu, että äänteiden esiintymistaajuus olisi universaalisti, kaikissa kielissä vallitsevana ilmiönä, kytköksissä niiden ääntämisen helppouteen siten, että yksinkertaisimmin ja helpoimmin äännettävät olisivat yleisimpiä. Oma materiaalini ei tue tätä käsitystä. Miksi soinnittomista klusiileista yleisjärjestyksessä 3. tilalla oleva t (9,88 % kaikista grafeemeista) olisi helpompi ääntää kuin 9. sijalla oleva k (5,27 %) tai peräti 18. sijalla oleva p (1,66 % kaikista)? Tai miksi 4. sijalla oleva dentaalinasaali n (8,67 %) olisi helpommin tuotettava kuin 12. sijalla oleva labiaalinasaali m (3,51 %); lapsenkielen tutkijathan ovat jossakin yhteydessä esittäneet, että lapsi oppii helpoimmin tuottamaan labiaaleja huulten toimintojen ensisijaisen kehittymisen takia.
Toisen oletuksen mukaan sellaiset kielessä taajaan esiintyvät lyhyet sanamuodot kuin esimerkiksi ja, siis, myös määräisivät grafeemien (suomen kielessä siis samalla foneemien) esiintymistaajuuden. Tämän tarkistamiseksi laskin grafeemit sellaisista sananmuodoista, jotka esiintyvät vähintään sata kertaa kussakin kolmessa kirjakielen materiaalini pääluokassa, nimittäin lehtikielessä, kaunokirjallisuuden kielessä ja tietokirjallisuuden kielessä. Tällaiseen otokseen ei edes keskipituisia sananmuotoja sovi mukaan kuin muutama. Lehtikielen aineiston kaikkien sananmuotojen keskipituus on 7,58, kaunokirjallisuuden kielen vain 6,39 ja tietokirjallisuuden kielen 7,80 grafeemia. Kuitenkin lehtikielessä yli 100 kertaa esiintyviä seitsengrafeemisia sananmuotoja on vain kaksi, jälkeen ja voidaan, kaunokirjallisuuden kielessä ei yhtään ja tietokirjallisuuden kielessä taajuusjärjestyksessä seuraavat 15: voidaan, jälkeen, lisäksi, yleensä, jolloin, tällöin, samalla, silloin, pykälän, jumalan, enemmän, valtion, päivänä, saadaan, tavalla. Otokseen kertyi vähän yli 20 % perusjoukon sananmuodoista, mutta vain noin 10 % saman perusjoukon grafeemeista, ja tällä tavalla laskettujen grafeemien keskinäinen järjestys ja prosenttiosuus poikkeaa monella tavalla perusjoukon grafeemien systeemeistä. Suurtaajuisimpien sananmuotojen grafeemisto ei ilmeisesti voi aiheuttaa eri tyyliluokissa esiintyviä grafeemien taajuusvaihteluita.
Miksi a, i, t, n, e, s, l?
Saneenloppuisten johtimien ja päätteiden osuuteen suomen murteiden kirjainnosten äännemerkkien taajuusvaihtelussa kiinnittivät ensiksi huomiota Anneli Pajunen ja Ulla Palomäki Lauseopin arkiston tekstejä tutkiessaan. Oletettavasti tällaiset morfemaattiset (taivutusopillisia aineksia sisältävät) tekijät vaikuttavat grafeemien esiintymistaajuuksiin ja niiden vaihteluihin myös kirjasuomessa. Tämän selvittämiseksi olen laskenut aineistostani lehtikielen (LEH, 106 170 sanetta, joissa 804 842 grafeemia), kaunokirjallisuuden kielen (KAU, 46 934 sanetta, 300 093 grafeemia) ja tietokirjallisuuden kielen (TIE, 177 695 sanetta, 1 386 273 grafeemia) pääluokista saneen lopusta lukien neljässä viimeisessä positiossa esiintyvät grafeemit. Seuraavassa taulukossa esitän yleisimpien grafeemien (a + ä =) A, i, t, n, e, s ja l esiintymistaajuudet1 näissä asemissa pääluokittain. Luvut ovat prosentteja kunkin pääluokan saman grafeemin kaikista esiintymistä. Sarakkeessa (-1) on saneenloppuinen grafeemi, sarakkeessa (-2) toiseksi viimeinen, (-3) kolmanneksi viimeinen ja (-4) neljäs lopusta lukien.
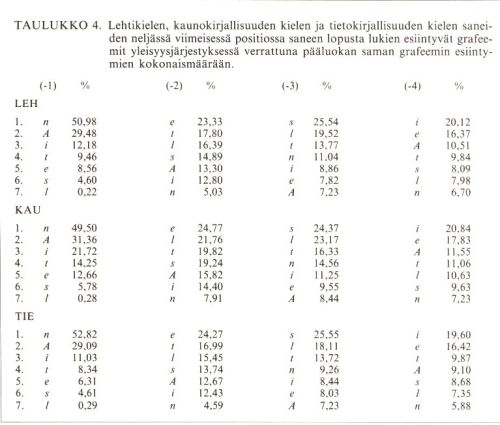
Taulukko 4(avautuu uuteen ikkunaan) (pdf)
Taulukko osoittaa siis, että kussakin pääluokassa grafeemin n kaikista esiintymistä noin puolet on saneen lopussa, A:sta samassa paikassa on noin 30 % ja i:stä luokissa LEH ja TIE noin 12 ja 11 %, mutta kaunokirjallisuuden luokassa peräti kaksinkertainen määrä eli yli 21 % luokan i:n koko määrästä. e:n kokonaismäärästä on huomattava osa (23,33–24,77 %) saneissa toiseksi viimeisenä, s:stä vastaavasti noin 25 % kolmanneksi viimeisenä ja vihdoin i:n esiintymistä noin 20 % saneissa neljänneksi viimeisenä.
Seuraavassa taulukossa esitän pääluokittain, kuinka monessa prosentissa pääluokan saneista seitsemän suurtaajuisinta grafeemia esiintyy neljässä viimeisessä positiossa. Luvut osoittavat siis prosentteja pääluokan saneiden määrästä. Samalla tavalla kuin edellisessäkin taulukossa on sarakkeessa (-1) saneenloppuinen grafeemi, sarakkeessa (-2) toiseksi viimeinen, (-3) kolmanneksi viimeinen ja (-4) neljäs lopusta lukien.
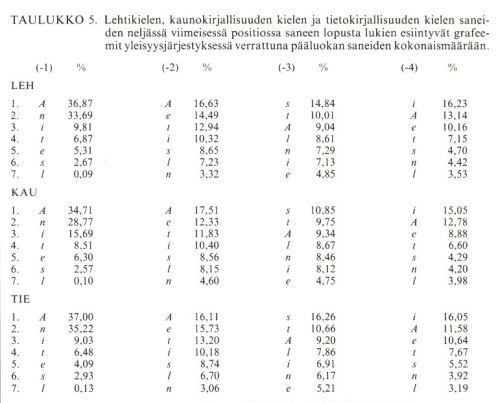
Taulukko 5 (pdf)
Taulukon osoittaman mukaisesti on siis A-loppuisia sananmuotoja kaikissa pääluokissa selvästi eniten (34,71–37,00 %). n-loppuisten saneiden määrä on lähes yhtä suuri (28,77–35,22 %), mutta i-loppuisten määrä on jo alle 10 % luokissa LEH ja TIE, kun taas luokassa KAU huomiota herättävästi peräti 15,69 %. Kaikissa pääluokissa on yleisin saneen loppu i s A A.
4. ja 5. taulukkoa tulkittaessa on otettava huomioon se, että positio (-1) on todella aina saneen viimeinen. Sen sijaan positioissa (-2), (-3) ja (-4) olevista grafeemeista osa on vastaavanpituisten saneiden alkugrafeemeja, jos kohta kunkin kuvatun kirjakielisen pääluokan saneiden keskipituus onkin lähellä seitsemää grafeemia (LEH 7,58; KAU 6,39 ja TIE 7,80). Taulukossa 4 esitetyt prosenttiluvut ovat tarkkoja arvoja, koska ne on laskettu kunkin kirjakielisen pääluokan vastaavan grafeemin esiintymien kokonaismäärästä, mutta 5. taulukon prosenttiluvut ovat vain likiarvoja, koska ne on laskettu saneiden esiintymien määrästä ottamatta huomioon saneiden pituutta, siis lyhyiden saneiden aiheuttamaa virhettä. Joka tapauksessa näinkin laskettuna ne antavat tietoa kirjakielemme saneenloppuisten grafeemijonojen rakenteesta sekä päätteissä, liitteissä ja johtimissa esiintyvien grafeemien taajuuksista.
Suomen kielen seitsemän suurtaajuisinta grafeemia ovat a, i, t, n, e, s, ja l. Nämä samat (+ ä) ovat useimmiten yleisimpiä myös saneiden lopussa neljässä viimeisessä positiossa. Fred Karlssonin mukaan ovat nominaalisessa sanastossamme perussanojen suosikkivartalot i- tai (a + ä =) A-loppuisia; varsin yleisiä ovat myös johtimien s, nen, jA, lA ja nA avulla muodostetut johdokset. Tyypillinen suomen kielen sijapääte koostuu useimmiten väljistä vokaaleista ja dentaalikonsonanteista; myös e ja i ovat niiden osina (A, llA, ItA, ssA, stA, tA, ttA, nA, Ile, n, den, ten, tten, en, ksi, kse, Vn2, hVn, seen, siin). Samaten persoonan ja omistuksen morfit, persoonaa ja omistajaa osoittavat kielenainekset, (n, t, mme, tte; mme, nne, nsA) sekä ajan, tavan ja luvun morfit (i, isi, ne, kO, kAA; i, f) muodostuvat pääosin näistä suurtaajuisista aineksista.Ilmeisesti huomattavimmat aineistoni kirjainmerkkien taajuusvaihtelut kuvastavat tällaisten sidonnaisten ilmimorfeemien tekstifrekvenssien vaihteluja erilaisissa ympäristöissä. Jos esimerkiksi kerrotaan menneistä ajoista tai tapahtumista käyttäen siihen useimmiten liittyvää aikaluokkaa, imperfektiä, nousee tällaisessa tekstissä i:n osuus yli keskimääräisen. Näyttää myös siltä, että saneenloppuiset grafeemijonot määräävät ainakin näiden suurtaajuisimpien grafeemien (ja suomen kielessä siis myös foneemien) keskinäisen yleisyysjärjestyksen. Päätteissä, liitteissä ja johtimissa yleisimmät grafeemit ovat myös yleisyystaulukon kärkisijoilla.
1Seuraavassa on vokaalien etu- ja takavokaaliset vaihteluparit (esim. talossa, kylässä) esitetty seuraavasti: a + ä = A, o + ö = O ja u + y = U.
2V on mikä vokaali tahansa.